先日、OpenAIから推論能力に優れた新しいAIモデル「o1(o1-preview / o1-mini)」シリーズが発表されました。
OpenAIの公式サイトでは、o1モデルの推論能力をわかりやすく紹介するため、GPT-4oとo1-previewに全く同じタスクを与えた場合の比較例が掲載されています。
oyfjdnisdr rtqwainr acxz mynzbhhx -> Think step by step
Use the example above to decode:
oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz
<日本語訳>
oyfjdnisdr rtqwainr acxz mynzbhhx -> Think step by step
上の例を使って次の暗号を解読してください。
oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz
たとえばこの「暗号」のタスクでは、GPT-4oの場合は暗号文を解読できませんでしたが、o1-previewでは1つのアプローチだけでなく、色々なパターンで思考プロセスを繰り返すことによって、最終的に暗号の解読に成功しています。
 GPT-4oでは失敗するが、o1-previewでは暗号解読に成功
GPT-4oでは失敗するが、o1-previewでは暗号解読に成功ところでこの暗号文はよく見ると、従来のOpenAIのモデルや他の生成AIが引っかかりやすいキーワードが含まれており、解読しづらい作りになっているようです。
そこで、GPT-4oでも暗号解読のコツをプロンプトに含めることで、o1-preview向けに用意された暗号文をうまく解読できないものか?実験してみることにしました。
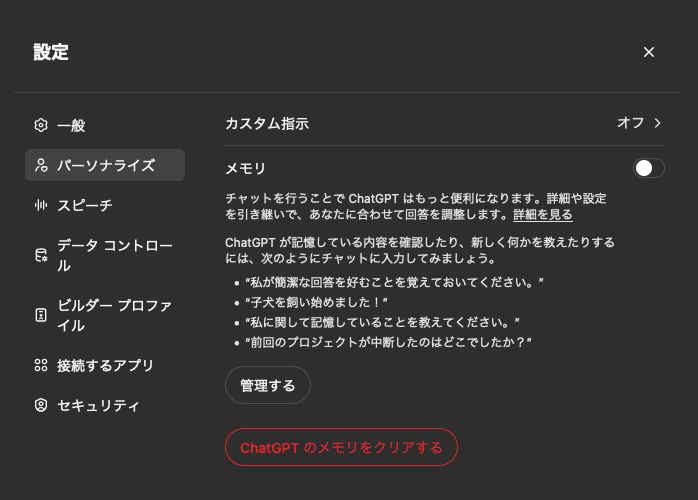 素のGPTで実験できるよう、カスタム指示とメモリをオフにします
素のGPTで実験できるよう、カスタム指示とメモリをオフにしますパーソナライズされていない素のGPTのままで実現できるかを確認するため、「メモリ」と「カスタム指示」をOFFにした上で、試しています。
また、チャット継続による学習を防ぐため、毎回新規チャットで開始しています。
基本的な暗号解読のコツ
暗号の解き方は色々ありますが、一般的に人間が暗号文を解読するときのコツとしては、いちばん短いキーワードに着目するとヒントが得られやすいです。
(というのを以前、家族に教えてもらって初めて知りました・・・)
oyfjdnisdr rtqwainr acxz mynzbhhx -> Think step by step
今回の例で言うと、最も短いキーワードが「acxz」で、解読後は「by」。
つまり「a」と「c」の間=「b」、「x」と「z」の間=「y」と推測できます。
文字列の最初の「o」と「y」を見ると、間にある文字は「o, p, q, r, s, t, u, v, w, x, y」であり、中央の文字は「t」。同様に、次の2文字の「f」と「j」の間の中央も「h」のため、この推測が正しいことがわかります。
同じ解き方で、
oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz
の文字列を変換していけば良いのですが、人の手で1つずつ調べていくのはどうしても時間がかかります。
そこで解き方のヒントさえAIに伝えれば、GPT-4oでも簡単に暗号解読できるのでは?と思ったのですが、LLMの性質上、そのままではうまくいかないことがわかりました。
 暗号の解き方を伝えても、解読に失敗するGPT-4o
暗号の解き方を伝えても、解読に失敗するGPT-4oAIの頭を悩ませるキーワード
1. “Think step by step”
暗号例に含まれているキーワード「Think step by step(ステップバイステップで考えてください)」は、プロンプトエンジニアリングでよく使われる手法で、LLMに段階的に思考させることで、回答に至るまでのプロセスを含めた詳しい情報を得ることができます。
ただ今回の場合、LLMはこの「Think step by step」をそのまま「ステップバイステップで考えてください」という指示だと捉えてしまい、暗号例の変換後であることを認識できず、結果として暗号解読まで至らない・・・というケースがよく見られました。
 「ステップバイステップで解読」という指示として受け取ってしまったGPT-4o
「ステップバイステップで解読」という指示として受け取ってしまったGPT-4o ステップ4まで考えてくれたが、暗号解読まで至らなかったGPT-4o
ステップ4まで考えてくれたが、暗号解読まで至らなかったGPT-4o2. 大文字の“T”
例として挙げられている暗号解読後の文章「Think step by step」では、「T」だけが大文字になっています。これは、AIに「T」の重要性を強調させ、暗号の解読のタスクから注意をそらしてしまうデメリットがあります。
実際には大文字であることに何も意味はなく、解読ルールに則ると逆に小文字のままで問題ないのですが、AIはこのイレギュラーな大文字の「T」に捉われてしまい、うまく暗号の解読ができない場合がありました。
 大文字のTに捉われてしまい、誤った解読をするGPT-4o
大文字のTに捉われてしまい、誤った解読をするGPT-4o3. 矢印を表す記号「->」
この矢印の記号「->」自体は現行のAIモデル、特にGPT-4oのような高度なモデルにとっては大きな混乱要因ではありません。たいていのAIモデルでは、様々な記号や表記に対応できるように訓練されています。
しかし、この暗号解読の文脈では、「->」が暗号文と解読文の区切りを示すものなのか、それとも暗号のプロセスの一部なのかを判断する必要があり、これが解釈の違いを生んでしまう可能性があります。
 「->」が変換後と認識できないため、やはり「step by step」に捉われるGPT-4o
「->」が変換後と認識できないため、やはり「step by step」に捉われるGPT-4oGPT-4oでも暗号解読できるプロンプト例

上記を踏まえ、AIが引っかかりやすいポイントを回避しつつ、GPT4でもo1-previewと同じように暗号を解読できるようなプロンプト例をご紹介します。
AIと人間で二人三脚といった感じですが、ちょっとした工夫をするだけで回答の精度を上げることができます。
1. 平易な文章でわかりやすく伝える
oyfjdnisdr rtqwainr acxz mynzbhhx -> think step by step
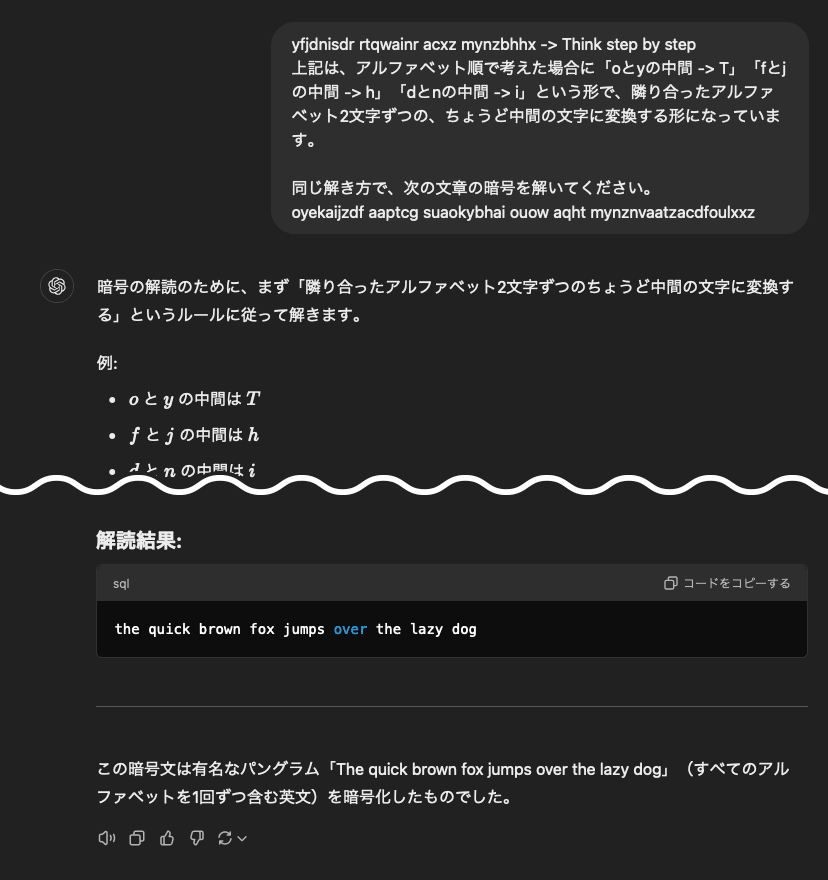
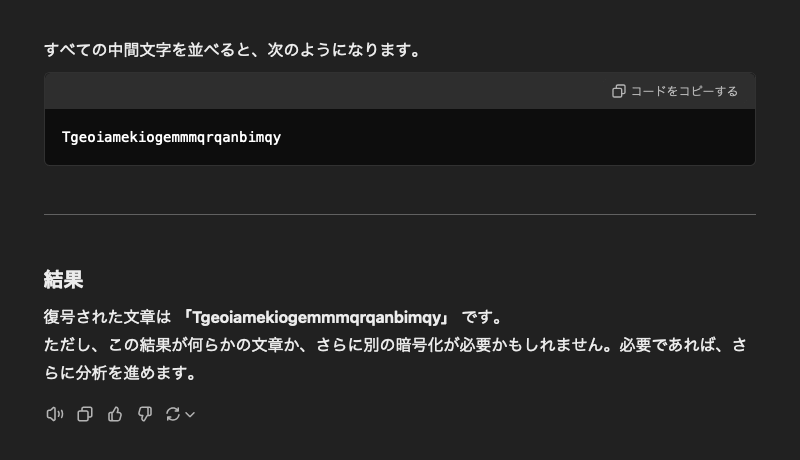
上記は、アルファベット順で考えた場合に「oとyの中間 -> t」「fとjの中間 -> h」「dとnの中間 -> i」という形で、隣り合ったアルファベット2文字ずつの、ちょうど中間の文字に変換する形になっています。同じ解き方で、次の文章の暗号を解いてください。
oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz
このプロンプト(というほどでもない、ただの文章)は、できるだけわかりやすく平易な言葉で記述しています。また、大文字の「T」を小文字の「t」に変更し、変換サンプルを複数加えることで「->」の意味が伝わりやすい形にしています。
大文字の「T」以外は失敗例と全く同じ指示ですが、GPT-4oはこれだけで「think step by step」に惑わされることが少なくなります。
 拙い指示でもきちんと暗号解読し、やる気満々のGPT-4o(可愛い)
拙い指示でもきちんと暗号解読し、やる気満々のGPT-4o(可愛い)なお、GPT-4以降のAIモデルはシンプルな指示が適しており、GPT-4oでも細かい条件や余分な情報までプロンプトに含めてしまうと、本来の力を発揮することができません。
たとえば、GPT-3.5までは有効とされていた役割(ロール)の付与や、「限界を超えてください」などのエモーショナルプロンプトは、かえってAIの思考の妨げとなります。
 不要な役割付与とエモーショナルプロンプトにより失敗してしまったGPT-4o
不要な役割付与とエモーショナルプロンプトにより失敗してしまったGPT-4oこのため、GPT-4oに指示を与えるときもできるだけシンプルな文章で記述し、内容を「解読例」「変換ルール」「解読してほしい暗号」の3つのみに絞っています。
2. マークダウン形式で伝える
# 解読する暗号文
```
oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz
```# 解読方法
* 暗号文の隣り合った2文字ごとに、そのアルファベット上の並び順でちょうど中央に位置する文字を見つけます。
* アルファベットは以下のように定義します:
```
a b c d e f g h i j k l m n o p q r s t u v w x y z
```## 例1
* ペア: a と c
* 並び順: a (1), b (2), c (3)
* 中央の文字: b## 例2
* ペア: x と z
* 並び順: x (24), y (25), z (26)
* 中央の文字: o## 半角スペースの扱い
半角スペースはそのまま残します。# 手順
* 暗号文を一文字ずつ読み取ります。
* 隣り合った文字をペアとして取り出します。
* 各ペアについて、上記の方法で中央の文字を特定します。
* 得られた文字を順に並べて、平文を作成します。
* スペースや特殊文字は位置を変えずにそのまま平文に含めます。# 目標
指定された手順で暗号文を解読し、最終的な平文を提供してください。
上記は、AIモデルが理解しやすいマークダウン形式で記述したプロンプトです。
プロンプトが長くなるほど本来のタスクを忘れてしまいがちなLLMですが、それを避けるために最初と最後に重要事項である「解読してほしい暗号」と「目標」を記述し、アルファベットの定義や並び順を数値に置換することで、精度を高めています。
3. コード、または疑似コードで指示する
今回の暗号は、アルファベット文字列の並び順と中央値を求めることで解読できるため、たとえばLLMが得意とするPythonコードや疑似コードを記述することで、暗号解読の方法をわかりやすく確実に伝えることができます。
# 下記のコードを実行してください。
import string
# アルファベットとそのインデックスの対応を取得
alphabet = string.ascii_lowercase
alphabet_index = {char: idx + 1 for idx, char in enumerate(alphabet)}
index_alphabet = {idx + 1: char for idx, char in enumerate(alphabet)}
def decode_middle_letter(encoded_text):
decoded_text = []
# 2文字ずつ区切って中間の文字を求める
for i in range(0, len(encoded_text), 2):
if i + 1 < len(encoded_text): # ペアが完成している場合のみ
char1, char2 = encoded_text[i], encoded_text[i + 1]
# インデックス取得(範囲外チェック)
idx1 = alphabet_index.get(char1, 0)
idx2 = alphabet_index.get(char2, 0)
# 中間のインデックスを計算
mid_idx = (idx1 + idx2) // 2
# 中間の文字を取得(インデックスに対応する文字)
decoded_char = index_alphabet.get(mid_idx, '?')
decoded_text.append(decoded_char)
return ''.join(decoded_text)
# 与えられた暗号をペアに分けて解読
cipher_text = "oyekaijzdf aaptcg suaokybhai ouow aqht mynznvaatzacdfoulxxz"
decoded_words = [decode_middle_letter(word) for word in cipher_text.split()]
decoded_sentence = ' '.join(decoded_words)
decoded_sentence
もはやほぼ答えを書いているようなものですが、AIの回答精度をできるだけ高くしたいという場合は、この方法が良さそうです。
上記のコードは、1で暗号解読と同時にGPTが記述してくれました。
また、実際のプログラミング言語ではなく、疑似コードを使うことも可能です。
下記は、GPTs用に例外処理などを追記したプロンプトの例です。
アルゴリズム: 文字列の中間文字による暗号解読
入力: 暗号文(アルファベット小文字とスペースで構成された文字列)
1. アルファベットマッピングの準備:
- a=1, b=2, c=3, ..., z=26 のように、各アルファベットに数値をマッピング
- 逆マッピングも用意(1=a, 2=b, 3=c, ..., 26=z)
2. メイン解読処理:
文章を単語ごとに分割して、各単語に対して以下を実行:
各単語の解読処理:
2.1. 入力単語を2文字ずつのペアに分割
2.2. 各ペアに対して:
a. 1文字目の数値(N1)を取得(例: 'p'なら16)
b. 2文字目の数値(N2)を取得(例: 'r'なら18)
c. 中間値を計算: M = (N1 + N2) ÷ 2 (小数点以下切り捨て)
d. 中間値(M)に対応するアルファベットを取得
e. 得られた文字を結果に追加
2.3. すべてのペアを処理し、得られた文字を連結
3. 解読された各単語をスペースで結合
出力: 解読された平文
例:
入力: "oyekaijzdf"
処理:
- "oy" → (15 + 25) ÷ 2 = 20 → 't'
- "ek" → (5 + 11) ÷ 2 = 8 → 'h'
- "ai" → (1 + 9) ÷ 2 = 5 → 'e'
など
注意事項:
- 入力は必ず小文字のアルファベットとスペースのみ
- 奇数長の単語の場合、最後の1文字は無視
- 存在しないアルファベットのペアの場合は'?'を出力同じタイプの暗号であれば、暗号文を入力するだけで解読してくれるため、繰り返し同じタスクを行わせたい場合に便利です。
まとめ

今回の記事では、o1-preview向けに用意された暗号文をGPT-4oでも解読できるのかどうかを試してみました。
o1モデルは高性能ですが、まだ機能や使用回数に制限がありコストも高いことから、OpenAI公式も状況に応じたモデルの使い分けを推奨しています。
そしてどのAIモデルを使う場合でも、結局は人間による検証が重要であることには変わりありません。
今回試してみた結果、回答サンプルと記述方法を少し工夫することで、GPT-4oでもo1モデルと同様の回答を得られることがわかりました。
実際の業務でLLMを利用する場合も、精度向上のために同じ工夫を行っているため、しばらくはGPT-4oを主力モデルとして使う機会が多そうです。
GPTの他愛もない実験でしたが、最後まで読んでいただきありがとうございました。

株式会社プレスマンは「ChatGPT Plus」のIT導入補助金2024支援事業者です。
IT支援事業者ならではの知見や充実したサポート体制を活かし、御社の事業成長に貢献いたします。
Web開発やDX推進でお悩みの場合は、ぜひお気軽にご相談ください。

AIの導入に躊躇されている企業様は、まずは1つのツールだけでも利用してみてはいかがでしょうか?EC×ChatGPTをはじめとしたAI企画から導入・運用まで、経験豊富な弊社プロ人材が手厚くサポートいたします。